AI Technical Writer

Introduction
Part 2: Knowledge Distillation, KV Caching, and Speculative Decoding
In Part 1, we saw how quantization reduces the numerical precision of model weights and how pruning removes redundant connections, both techniques that target the model itself before it ever sees a request.
Part 2 takes a different angle. The three techniques covered here optimize model inference from different directions: Knowledge Distillation trains a smaller, faster model to behave like a larger one. KV Caching eliminates redundant computation at runtime by storing and reusing intermediate attention states. Speculative Decoding parallelizes what is, by design, a sequential process, thus making the GPU do multiple tokens’ worth of work in the time it would normally do one.
Together, they represent the most impactful techniques for making LLMs fast and deployable in production, and not just making them a theoretical concept, but actually responsive at scale.
By the end of this article, we will learn how each technique works at the algorithm level, where they fit in a real inference pipeline, and how they compose with the techniques from Part 1 to build a fully optimized serving stack.
Key Takeaways
- Knowledge Distillation transfers the “soft knowledge” encoded in a large model’s probability distributions into a smaller student model — not just the final answers. Instead of learning only the final prediction, the smaller model also learns from the confidence levels the larger model assigns to different tokens. This helps the smaller model perform better than its size would normally suggest.
- KV Caching is the single most impactful runtime optimization in standard LLM serving. Without it, generating each new token requires recomputing attention over the entire context from scratch — an O(n²) operation. With it, we only process the new token.
- PagedAttention solves KV cache fragmentation — the hidden memory waste from over-allocating cache space for sequences that never reach max length. It’s the core innovation behind vLLM’s throughput advantages.
- Speculative Decoding exploits an asymmetry: verifying K candidate tokens in parallel is cheaper than generating K tokens sequentially. A fast draft model speculates; the large model verifies — and we get the exact same output distribution as running the large model alone, just faster.
- EAGLE-2 and Medusa bring speculative decoding into production without requiring a separate draft model — making the technique accessible even when we are deploying a single model.
Knowledge Distillation
The Core Idea
Imagine there is a professor who knows everything, and a student who needs to pass the same exam. The naive approach: give the student the same textbooks and hope for the best. The smarter approach: have the professor explain why each answer is right, not just what the answer is.
That’s knowledge distillation in one sentence. The “professor” is a large, powerful teacher model. The “student” is a smaller, faster student model. The goal isn’t just to get the student to produce the same outputs but rather to get the student to absorb the same reasoning patterns encoded in the teacher’s probability distributions.
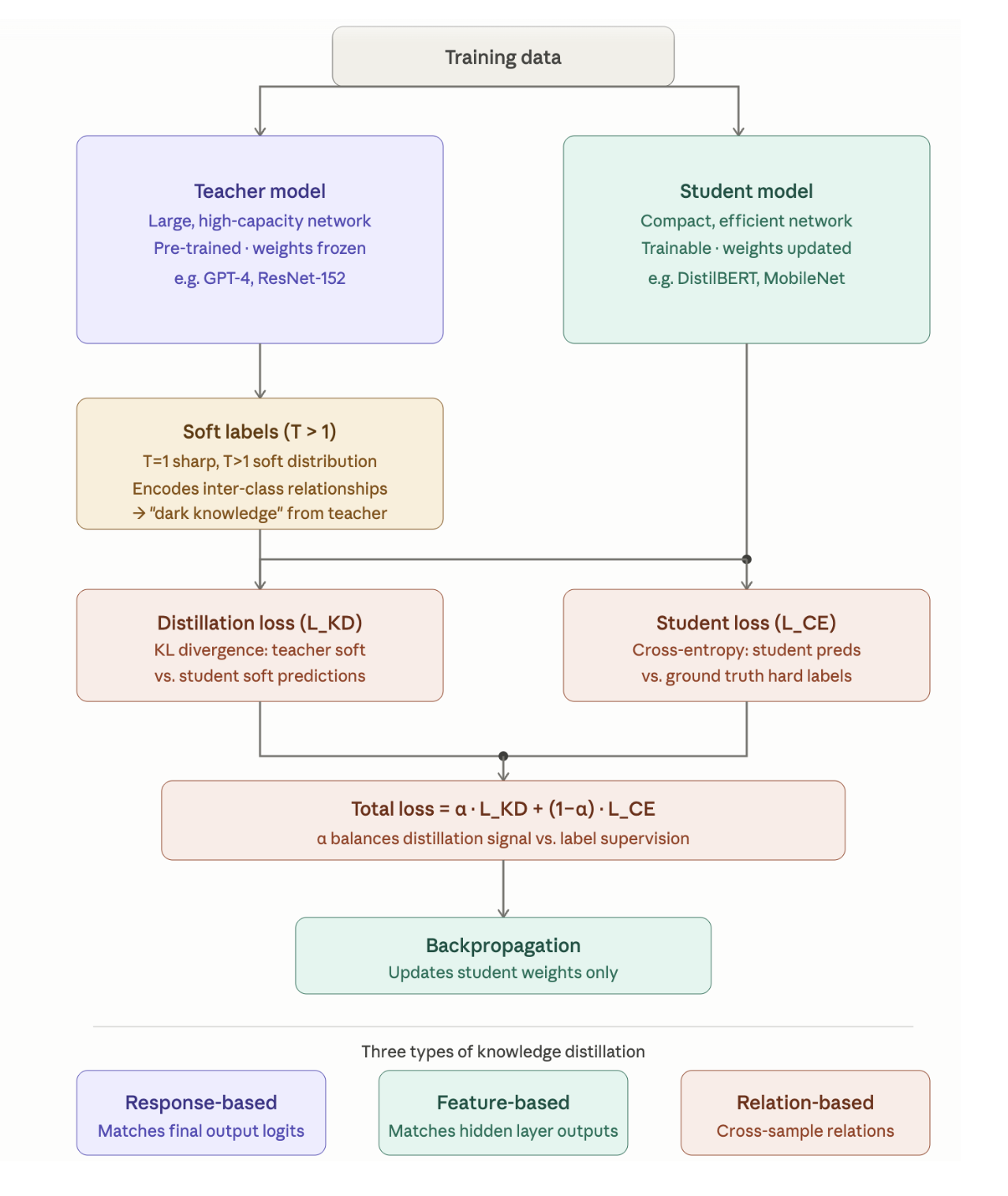
Why Probability Distributions Carry More Information Than Labels
When a teacher model assigns probabilities to tokens, the distribution itself is informative. If the teacher outputs:
“dog”: 0.72, “wolf”: 0.18, “cat”: 0.06, “fox”: 0.04
This tells the student far more than the hard label "dog". It says: dog and wolf are semantically related, this is a close call, and cat and fox are plausible but distant. A student trained only on hard labels would never see that signal.
This is the central insight of Hinton et al.'s 2015 distillation paper: soft labels are richer supervisory signals than hard labels.
The Loss Function
The training objective combines two losses:
Cross-entropy loss on hard labels (standard supervised learning):
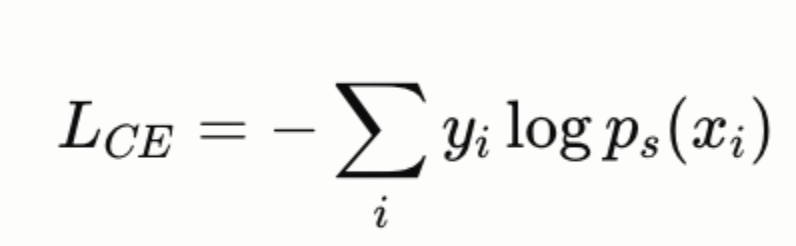
KL divergence loss between teacher and student distributions, computed at temperature T:
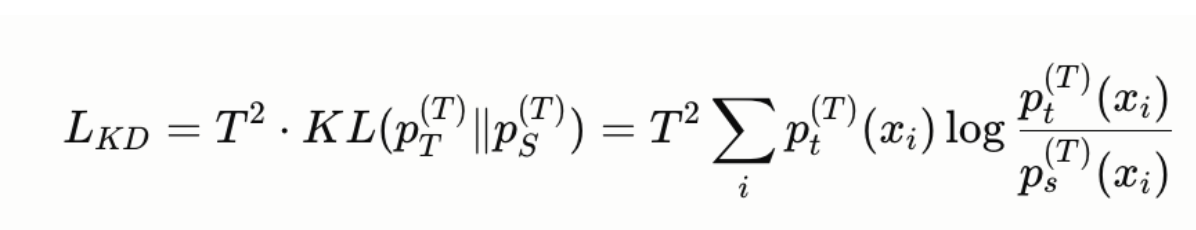
The factor T² compensates for the fact that soft targets at high temperature have smaller gradients. The combined loss is:
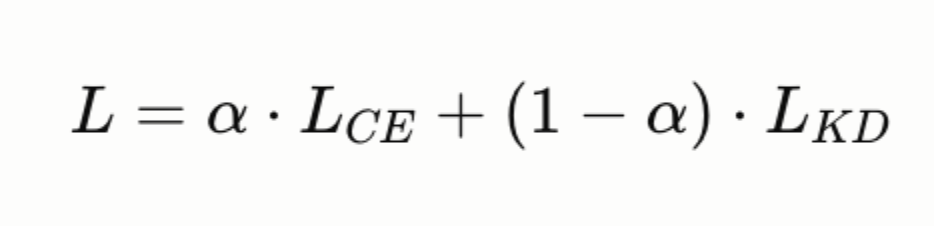
where α controls how much weight we give to ground truth labels vs. teacher guidance. In practice, α = 0.1–0.5 works well — we want the teacher’s signal to dominate.
Temperature T > 1 softens the teacher’s distribution, making it less peaked. This amplifies the signal in the smaller probability values (the “dark knowledge”) that would otherwise be drowned out by the dominant token’s probability. A typical value is T = 2–4.
Distillation Flavors
Response-Based Distillation is the simplest: the student learns from the teacher’s final output logits. No access to the teacher’s internals is needed. This is what DistilBERT and TinyLLaMA use.
Feature-Based Distillation goes deeper. The student is also trained to mimic the teacher’s intermediate hidden states — the activations at specific layers. The intuition: a layer’s hidden state encodes its learned representation of the input. If the student’s hidden states look like the teacher’s, the student has internalized not just what to predict, but how to reason about the input.
The loss for a given layer pair (student layer s, teacher layer t) is:
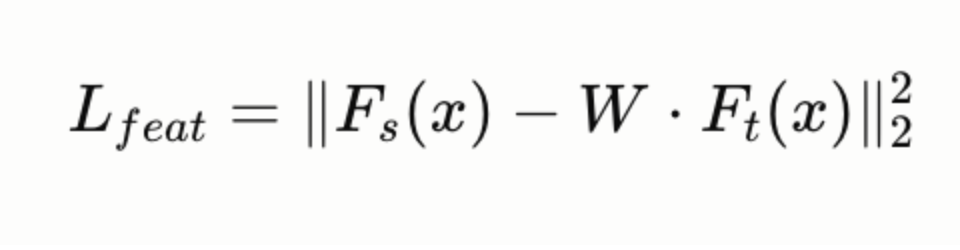
where W is a learned projection matrix that maps teacher feature dimensions to student feature dimensions (necessary when they differ).
Relation-Based Distillation transfers pairwise relationships between samples — rather than matching individual activations, the student learns to preserve the similarity structure of the teacher’s representation space.
Patient Knowledge Distillation (PKD)
Standard distillation only uses the teacher’s final layer. PKD proposes using multiple intermediate layers of the teacher as supervision signals. The student “patiently” learns from every layer of the teacher, not just the output.
This is particularly effective for BERT-style encoders, where intermediate representations encode increasingly abstract linguistic features. A student trained with PKD converges faster and retains more of the teacher’s internal knowledge at lower parameter counts.
MiniLLM: Fixing the Mode-Averaging Problem
Forward KL divergence (used in standard distillation) minimizes:
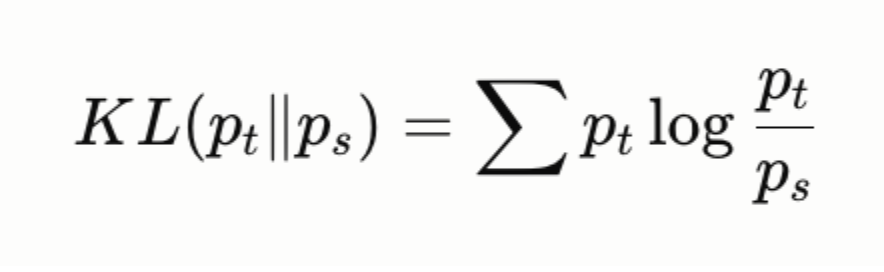
This penalizes the student heavily when p_s is small, but p_t is large — meaning the student is forced to cover all the modes of the teacher’s distribution, including low-probability ones. For autoregressive text generation, this causes mode averaging: the student spreads probability mass across many plausible continuations, producing generic, hedging outputs.
MiniLLM flips the direction:
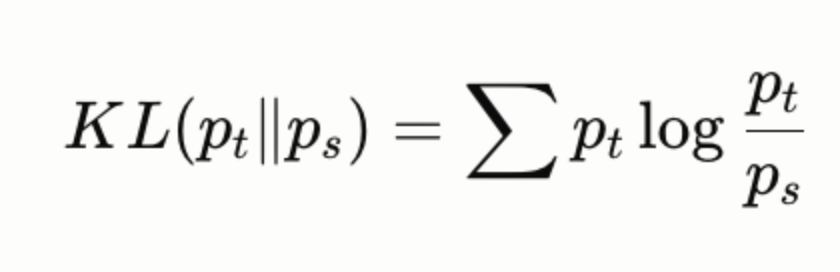
Reversed KL penalizes the student for putting probability mass where the teacher doesn’t — it encourages mode-seeking rather than mode-covering. The student learns to pick the most confident, high-quality continuations rather than averaging across all plausible ones.
MiniLLM also addresses exposure bias: during standard training, the student always sees ground-truth prefixes, but at inference, it conditions on its own outputs. MiniLLM uses policy gradient optimization over the student’s own generated sequences, which closes this train-inference gap.
Python Example: Teacher-Student Distillation Training Loop
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.utils.data import DataLoader
class DistillationTrainer:
def __init__(
self,
teacher_model,
student_model,
temperature: float = 2.0,
alpha: float = 0.5,
device: str = "cuda"
):
self.teacher = teacher_model.to(device).eval()
self.student = student_model.to(device)
self.T = temperature
self.alpha = alpha
self.device = device
# Freeze teacher — it's a fixed oracle
for param in self.teacher.parameters():
param.requires_grad = False
def distillation_loss(self, student_logits, teacher_logits, labels):
"""
Combines hard-label cross-entropy with soft-label KL divergence.
student_logits: [batch, seq_len, vocab_size]
teacher_logits: [batch, seq_len, vocab_size]
labels: [batch, seq_len] — ground truth token IDs
"""
# --- Hard label loss (standard language modeling) ---
# Shift so that token n predicts token n+1
shift_logits = student_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
L_ce = F.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
ignore_index=-100
)
# --- Soft label loss (KL divergence at temperature T) ---
# Apply temperature scaling to both teacher and student
soft_teacher = F.softmax(teacher_logits[..., :-1, :] / self.T, dim=-1)
soft_student = F.log_softmax(student_logits[..., :-1, :] / self.T, dim=-1)
# T^2 scaling compensates for reduced gradient magnitudes at high T
L_kd = (self.T ** 2) * F.kl_div(
soft_student,
soft_teacher,
reduction="batchmean"
)
# Combined loss
return self.alpha * L_ce + (1 - self.alpha) * L_kd
def train_step(self, input_ids, attention_mask, optimizer):
input_ids = input_ids.to(self.device)
attention_mask = attention_mask.to(self.device)
# Teacher forward pass (no gradients needed)
with torch.no_grad():
teacher_out = self.teacher(
input_ids=input_ids,
attention_mask=attention_mask
)
teacher_logits = teacher_out.logits
# Student forward pass (gradients flow here)
student_out = self.student(
input_ids=input_ids,
attention_mask=attention_mask
)
student_logits = student_out.logits
# Compute distillation loss
loss = self.distillation_loss(student_logits, teacher_logits, input_ids)
# Backprop on student only
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
def run_distillation(teacher_name, student_name, dataset, epochs=3, lr=1e-4):
"""
Example: distill Mistral-7B → TinyLLaMA-1.1B
"""
teacher = AutoModelForCausalLM.from_pretrained(teacher_name, torch_dtype=torch.float16)
student = AutoModelForCausalLM.from_pretrained(student_name, torch_dtype=torch.float32)
trainer = DistillationTrainer(
teacher_model=teacher,
student_model=student,
temperature=2.0,
alpha=0.3 # 30% hard labels, 70% teacher guidance
)
optimizer = torch.optim.AdamW(student.parameters(), lr=lr)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for epoch in range(epochs):
total_loss = 0.0
for batch in dataloader:
loss = trainer.train_step(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
optimizer=optimizer
)
total_loss += loss
avg_loss = total_loss / len(dataloader)
print(f"Epoch {epoch+1}/{epochs} | Loss: {avg_loss:.4f}")
return student
Distillation is the right tool when we need a model small enough to run on edge hardware, or cheap enough to serve at scale, but we can’t afford to start from scratch. Common scenarios: a 1.1B model distilled from LLaMA-2-7B for on-device inference; domain-specific distillation where a fine-tuned 13B teacher transfers domain expertise into a 1B student; or capability distillation for narrow tasks like SQL generation or code completion, where a large general model teaches a small specialized one.
Importantly, distillation and quantization compose cleanly. The typical pipeline is: distill first (model compression), then quantize (weight compression), then deploy with the runtime optimizations below.
KV Cache
Why Attention Has a Memory Problem
To understand KV caching, we first need to understand what happens during autoregressive text generation without it.
In a transformer’s attention mechanism, for each token position i, the model computes three vectors: Query (Q), Key (K), and Value (V). The attention output at position i is:
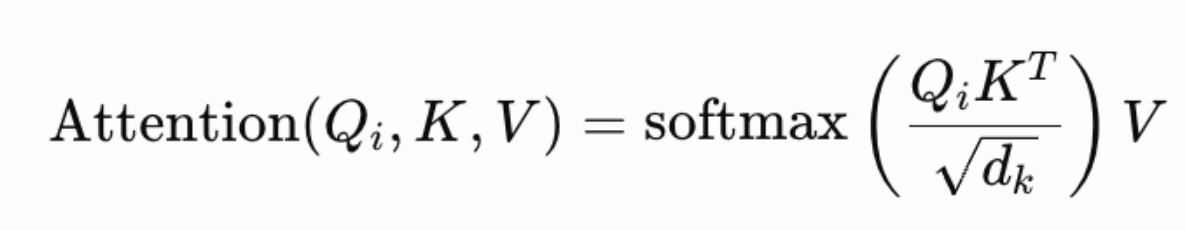
Here, K and V span all previous positions — the model attends to its entire context to decide what the next token should be.
Now consider what happens when we generate token 101. We need K and V for tokens 1 through 100. Then, for token 102, we need K and V for tokens 1 through 101. If we are not caching, we are recomputing K and V for tokens 1–100 from scratch every single step. That’s O(n) redundant computation per token, leading to O(n²) total, and it gets worse as sequences grow longer.
KV caching simply stores the K and V matrices as we compute them and appends to the cache with each new token. At step n, we only compute K, V for the new token, then concatenate with the cache. Suddenly, attention over long contexts is O(1) per step.
The Memory Cost of Caching
KV cache is not free — it trades compute for memory. The cache size for a single sequence is:
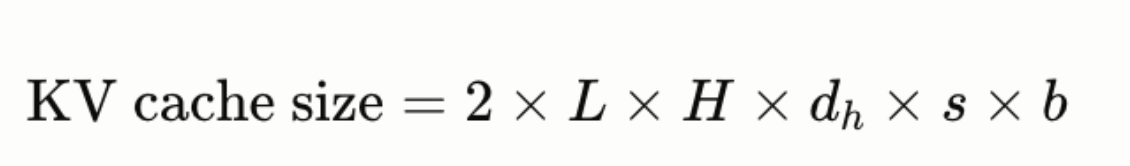
where L is the number of layers, H is the number of KV heads, d_h is head dimension, s is sequence length, and b is bytes per element.
For LLaMA-2-7B at FP16 (2 bytes per element):
- L = 32 layers, H = 32 heads, d_h = 128, at sequence length 4096
- KV cache = 2 × 32 × 32 × 128 × 4096 × 2 = 4.29 GB
That’s just for one sequence. At a batch size of 16, we are looking at 68 GB of KV cache alone — before even fitting the model weights.
This is why the architecture of attention heads matters enormously for inference efficiency.
Multi-Head vs Multi-Query vs Grouped-Query Attention
These three attention variants represent different trade-offs between quality and KV cache size:
Multi-Head Attention (MHA) — the original transformer design. Each attention head has its own independent K and V projections. For H heads, we store H × 2 matrices per layer. Maximum expressiveness, maximum memory cost.
Multi-Query Attention (MQA) — all H attention query heads share a single K head and a single V head. Reduces KV cache by a factor of H (typically 8–32×). The catch: quality degrades, especially on tasks requiring diverse attention patterns. Used in PaLM, Falcon.
Grouped-Query Attention (GQA) — a middle ground. Query heads are divided into G groups, each group sharing one K and one V head. With G groups, the KV cache is reduced by H/G. LLaMA-2-70B uses G=8 (from 64 query heads, 8 KV heads), reducing KV cache by 8× with minimal quality loss. LLaMA-3 and Mistral use GQA across all model sizes.
MHA: [Q1,Q2,...,QH] → [K1,K2,...,KH], [V1,V2,...,VH] # H KV pairs
GQA: [Q1..Q8] → [K1,V1], [Q9..Q16] → [K2,V2], ... # G KV pairs (G << H)
MQA: [Q1..QH] → [K1,V1] # 1 KV pair
PagedAttention: Solving the Fragmentation Problem
Even with GQA reducing cache size, naive KV cache management wastes memory. The standard approach reserves max_seq_len contiguous blocks of GPU memory for each sequence at request start. If max_seq_len is 4096 but the actual response is 200 tokens, we have wasted 3896 tokens’ worth of cache. With hundreds of concurrent requests, this fragmentation causes GPU memory utilization of 20–40%.
PagedAttention, the core innovation in vLLM, borrows the solution from the operating system virtual memory: paging.
Instead of contiguous pre-allocation, PagedAttention divides the KV cache into fixed-size blocks (pages), each holding K and V for a fixed number of tokens (e.g., 16). A block table maps each sequence’s logical positions to physical blocks. Blocks are allocated on demand as the sequence grows, and freed immediately when the sequence completes.
The result: GPU memory utilization above 90%, enabling 2-4× higher throughput compared to naive implementations. vLLM also uses paging to enable copy-on-write for parallel sampling — multiple response candidates share the same KV cache blocks for the prompt, with blocks only duplicated when their content diverges.
Python Example: KV Cache in Attention
Here’s a minimal implementation showing how KV caching works in a multi-head attention layer — the mechanics vLLM and other frameworks build on:
import torch
import torch.nn as nn
import torch.nn.functional as F
from dataclasses import dataclass, field
from typing import Optional, Tuple
@dataclass
class KVCache:
"""
Stores accumulated Key and Value tensors across generation steps.
Shape: [batch, n_heads, seq_len, head_dim]
"""
keys: Optional[torch.Tensor] = None
values: Optional[torch.Tensor] = None
def update(self, new_keys: torch.Tensor, new_values: torch.Tensor):
"""Append new K, V to the cache along the sequence dimension."""
if self.keys is None:
self.keys = new_keys
self.values = new_values
else:
self.keys = torch.cat([self.keys, new_keys], dim=2) # dim=2 is seq_len
self.values = torch.cat([self.values, new_values], dim=2)
return self.keys, self.values
@property
def seq_len(self) -> int:
return self.keys.shape[2] if self.keys is not None else 0
class CachedMultiHeadAttention(nn.Module):
def __init__(self, d_model: int, n_heads: int):
super().__init__()
assert d_model % n_heads == 0
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.scale = self.head_dim ** -0.5
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, d_model, bias=False)
self.v_proj = nn.Linear(d_model, d_model, bias=False)
self.o_proj = nn.Linear(d_model, d_model, bias=False)
def _split_heads(self, x: torch.Tensor) -> torch.Tensor:
"""[batch, seq, d_model] → [batch, n_heads, seq, head_dim]"""
B, S, D = x.shape
return x.view(B, S, self.n_heads, self.head_dim).transpose(1, 2)
def forward(
self,
x: torch.Tensor, # [B, seq_len, d_model] — current token(s)
kv_cache: Optional[KVCache] = None,
use_causal_mask: bool = True
) -> Tuple[torch.Tensor, KVCache]:
B, S, _ = x.shape
# Project Q, K, V for the current input
Q = self._split_heads(self.q_proj(x)) # [B, H, S, head_dim]
K = self._split_heads(self.k_proj(x)) # [B, H, S, head_dim]
V = self._split_heads(self.v_proj(x)) # [B, H, S, head_dim]
# Update cache — appends new K, V; returns full history
if kv_cache is not None:
K, V = kv_cache.update(K, V)
# K, V now have shape [B, H, total_seq_len, head_dim]
# Attention: Q over full K, V history
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) * self.scale
# attn_scores: [B, H, current_seq, total_seq]
if use_causal_mask:
total_len = K.shape[2]
current_len = Q.shape[2]
# Mask: each query position can attend to all cached + current positions up to its own
mask = torch.triu(
torch.ones(current_len, total_len, device=x.device),
diagonal=total_len - current_len + 1
).bool()
attn_scores = attn_scores.masked_fill(mask, float('-inf'))
attn_weights = F.softmax(attn_scores, dim=-1)
out = torch.matmul(attn_weights, V) # [B, H, current_seq, head_dim]
# Merge heads: [B, H, S, head_dim] → [B, S, d_model]
out = out.transpose(1, 2).contiguous().view(B, S, -1)
return self.o_proj(out), kv_cache
def autoregressive_generate(model, tokenizer, prompt: str, max_new_tokens: int = 50):
"""
Demonstrate KV cache reuse across generation steps.
"""
tokens = tokenizer(prompt, return_tensors="pt")["input_ids"]
# --- Prefill phase: process the entire prompt at once ---
# This fills the cache with K, V for all prompt tokens
kv_cache = KVCache()
with torch.no_grad():
output, kv_cache = model(tokens, kv_cache=kv_cache)
# --- Decode phase: one token at a time, reusing cache ---
generated = []
next_token = output[:, -1:, :] # last token's representation
for step in range(max_new_tokens):
# Only feed the NEW token — cache handles the history
new_token_id = next_token.argmax(dim=-1) # simplified greedy sampling
new_token_embed = model.embed(new_token_id) # [B, 1, d_model]
with torch.no_grad():
output, kv_cache = model(new_token_embed, kv_cache=kv_cache)
token_id = output[:, -1, :].argmax(dim=-1).item()
generated.append(token_id)
next_token = output[:, -1:, :]
# Cache grows by 1 token per step — no recomputation
print(f"Step {step+1}: cache size = {kv_cache.seq_len} tokens")
if token_id == tokenizer.eos_token_id:
break
return tokenizer.decode(generated)
KV Cache Eviction: Handling Very Long Contexts
For sequences exceeding available GPU memory, we can’t keep the full cache. Eviction policies selectively discard K, V entries:
StreamingLLM keeps two regions: the first few “attention sink” tokens (which empirically attract disproportionate attention even when irrelevant) and a sliding window of recent tokens. This allows infinite-length generation with a fixed memory budget, at the cost of mid-sequence context.
H2O (Heavy Hitter Oracle) tracks cumulative attention scores for each token across all layers. Tokens that have received the most attention historically are “heavy hitters” — they’re likely to be attended to again and are retained. Low-attention tokens are evicted. H2O achieves near-full-cache quality at 20% cache size on many tasks.
SnapKV takes a query-centric approach: for each new query vector, it identifies which cached keys it attends to most, and uses that to decide what to evict. The insight is that the currently active query is the best signal for what context is relevant right now.
Prefix Caching
For applications where many requests share a common prefix — a system prompt, a document, a RAG context — recomputing the KV cache for that prefix on every request is pure waste.
Prefix caching (also called RadixAttention in SGLang) stores K, V for known prefixes in a persistent cache. Incoming requests that share a prefix get their cache pre-populated. vLLM supports automatic prefix caching, which can reduce time-to-first-token by 50–90% for chatbot workloads where the system prompt is long and shared.
KV caching is universally applicable — every production LLM serving system uses it. The higher-level optimizations (GQA, PagedAttention, prefix caching) matter most when:
- We are serving long-context models (32K+ tokens) where cache size is the binding constraint
- We are running high-concurrency workloads where memory fragmentation degrades throughput
- We are building a chatbot or RAG pipeline where prompt prefixes repeat across requests
KV cache quantization (storing K, V in INT8 instead of FP16) is a practical way to double effective cache capacity at minimal quality cost — particularly valuable on memory-constrained hardware.
Speculative Decoding
The Sequential Bottleneck
LLM inference is, at its core, a sequential process. We generate token 1, then token 2, then token 3 — each step conditioned on all previous outputs. This is an inherent constraint of autoregressive generation.
But there’s a deeper problem: modern LLM inference is memory-bandwidth bound, not compute-bound. Each forward pass spends most of its time loading weights from GPU HBM into compute units — not doing arithmetic. A small model and a large model of the same size aren’t that different in terms of how long a single forward pass takes, because both are bottlenecked by memory bandwidth, not FLOPs.
Speculative decoding exploits a surprising insight: verifying a sequence of K tokens in parallel is roughly the same cost as verifying one token. This is because verification is a single forward pass of the large model, and a forward pass over a sequence of K tokens costs almost the same as a forward pass over 1 token, since the batch of K tokens is processed in parallel by the transformer.
The Algorithm
The algorithm has two actors:
Draft model — a small, fast model (e.g., a 7B verifying against a 70B, or a 0.5B verifying against a 7B). The draft model generates K candidate tokens autoregressively. Because it’s small, this is fast and cheap.
Target model — the large model whose output distribution we want to match. It verifies all K draft tokens in a single parallel forward pass, computing its own probability distribution at each draft position.
Acceptance/rejection works via token-level rejection sampling:
For each draft token xiat position i:
- Compute r∼Uniform(0,1)
- If r < min(1, ptarget(xi)/pdraft(xi)), accept xi
- Otherwise, reject and sample from the residual distribution:
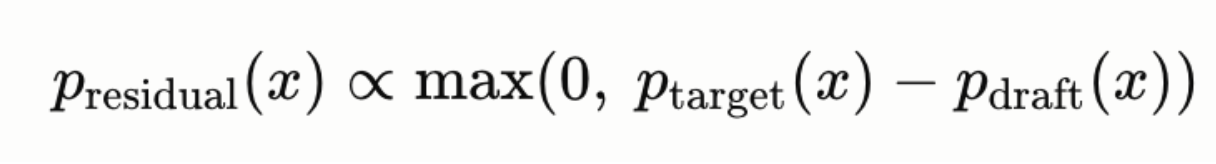
Stop at the first rejection. The target model then samples one more token from its own distribution. The critical property: the accepted tokens follow exactly the target model’s distribution. Speculative decoding isn’t an approximation — it produces output statistically identical to running the large model alone, just faster. This is mathematically provable.
The expected number of tokens generated per target model call is:
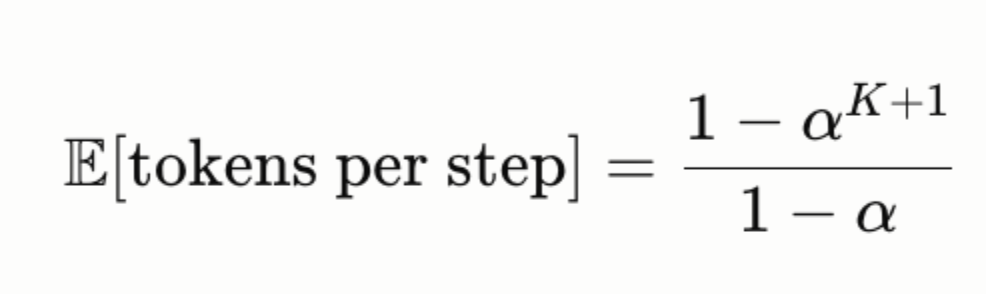
where α is the per-token acceptance rate. At α = 0.8 and K = 4, we get ~3.4 tokens per target model call — a 3.4× speedup in token throughput.
Python Example: Speculative Decoding from Scratch
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
from typing import List, Tuple
def speculative_decode(
draft_model,
target_model,
tokenizer,
prompt: str,
max_new_tokens: int = 100,
K: int = 4, # draft tokens per round
temperature: float = 1.0,
device: str = "cuda"
) -> Tuple[str, dict]:
"""
Full speculative decoding loop.
Returns generated text and stats (acceptance rate, speedup).
"""
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generated = input_ids.clone()
stats = {"accepted": 0, "rejected": 0, "rounds": 0}
draft_model.eval()
target_model.eval()
while generated.shape[1] - input_ids.shape[1] < max_new_tokens:
stats["rounds"] += 1
# ── Step 1: Draft model generates K candidate tokens ──────────────
draft_tokens = []
draft_probs = []
draft_input = generated.clone()
with torch.no_grad():
for _ in range(K):
draft_out = draft_model(draft_input)
logits = draft_out.logits[:, -1, :] / temperature
probs = F.softmax(logits, dim=-1)
# Sample from draft distribution
next_token = torch.multinomial(probs, num_samples=1)
draft_tokens.append(next_token)
draft_probs.append(probs)
draft_input = torch.cat([draft_input, next_token], dim=1)
# draft_tokens: list of K tensors [batch, 1]
# draft_probs: list of K tensors [batch, vocab_size]
# ── Step 2: Target model verifies all K tokens in ONE forward pass ──
# Build sequence: original + K draft tokens
candidate_sequence = torch.cat([generated] + draft_tokens, dim=1)
with torch.no_grad():
target_out = target_model(candidate_sequence)
# Extract target logits at the K positions being verified
# Position offset: logits[i] predicts token at position i+1
target_logits = target_out.logits[:, generated.shape[1]-1:-1, :] / temperature
target_probs = F.softmax(target_logits, dim=-1) # [batch, K, vocab_size]
# ── Step 3: Token-level rejection sampling ──────────────────────────
n_accepted = 0
new_tokens = []
for i in range(K):
draft_token_id = draft_tokens[i].squeeze(-1) # [batch]
p_target = target_probs[:, i, :] # [batch, vocab]
p_draft = draft_probs[i] # [batch, vocab]
# Acceptance probability: min(1, p_target / p_draft)
token_idx = draft_token_id.unsqueeze(-1) # [batch, 1]
p_t = p_target.gather(1, token_idx).squeeze() # [batch]
p_d = p_draft.gather(1, token_idx).squeeze() # [batch]
accept_prob = torch.minimum(
torch.ones_like(p_t),
p_t / (p_d + 1e-10)
)
r = torch.rand_like(accept_prob)
accepted = r < accept_prob
if accepted.all():
new_tokens.append(draft_tokens[i])
n_accepted += 1
stats["accepted"] += 1
else:
# Reject: sample from residual distribution
# p_residual ∝ max(0, p_target - p_draft)
residual = torch.clamp(p_target - p_draft, min=0.0)
residual = residual / (residual.sum(dim=-1, keepdim=True) + 1e-10)
corrected_token = torch.multinomial(residual, num_samples=1)
new_tokens.append(corrected_token)
stats["rejected"] += 1
break # Stop at first rejection
# ── Step 4: If all K accepted, sample one bonus token from target ──
if n_accepted == K:
bonus_logits = target_out.logits[:, -1, :] / temperature
bonus_probs = F.softmax(bonus_logits, dim=-1)
bonus_token = torch.multinomial(bonus_probs, num_samples=1)
new_tokens.append(bonus_token)
# Append accepted tokens to generated sequence
for t in new_tokens:
generated = torch.cat([generated, t], dim=1)
# Check for EOS
if tokenizer.eos_token_id in new_tokens[-1]:
break
# Compute stats
total_tokens = stats["accepted"] + stats["rejected"]
alpha = stats["accepted"] / max(total_tokens, 1)
stats["acceptance_rate"] = alpha
stats["effective_tokens_per_round"] = total_tokens / max(stats["rounds"], 1)
output_ids = generated[0, input_ids.shape[1]:]
return tokenizer.decode(output_ids, skip_special_tokens=True), stats
# Usage
def demo():
draft_model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
target_model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(target_model_name)
draft_model = AutoModelForCausalLM.from_pretrained(draft_model_name, torch_dtype=torch.float16)
target_model = AutoModelForCausalLM.from_pretrained(target_model_name, torch_dtype=torch.float16)
prompt = "Explain the difference between a kernel and a hypervisor:"
text, stats = speculative_decode(
draft_model, target_model, tokenizer, prompt,
max_new_tokens=200, K=4
)
print(f"Generated: {text}")
print(f"Acceptance rate: {stats['acceptance_rate']:.2%}")
print(f"Avg tokens per round: {stats['effective_tokens_per_round']:.2f}")
print(f"Theoretical speedup: ~{stats['effective_tokens_per_round']:.1f}x")
Beyond Basic Speculative Decoding
EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency)
The weakness of basic speculative decoding is that we need a separate draft model, and finding one that’s both fast and has a high acceptance rate against the target is non-trivial.
EAGLE eliminates the separate draft model. Instead, it adds a lightweight feature prediction head directly to the target model. This head predicts the model’s own next-layer hidden state rather than the next token. The prediction is cheap (one small MLP + one transformer layer), and because it operates in the target model’s feature space, acceptance rates are very high (0.8–0.9).
EAGLE-2 goes further by using dynamic draft trees — instead of always generating exactly K tokens, it builds a tree of candidates and dynamically prunes branches with low acceptance probability. The tree depth adapts based on the current context, generating more candidates when confidence is high.
Results: EAGLE-2 achieves 3–4× speedup over greedy decoding, compared to 2–2.5× for basic speculative decoding with a separate draft model.
Medusa
Medusa adds multiple decoding heads directly to the base model, each predicting the token at position n+k (for k = 1, 2, …, K). All heads run in parallel on the same hidden state from the last layer — no additional forward passes needed.
At verification time, Medusa uses tree attention: it builds a candidate tree from all head predictions and runs a single masked attention pass over all candidates simultaneously. This verifies the entire tree in one forward pass.
Medusa’s advantage: it’s self-contained. No draft model, no separate architecture. Just K additional linear heads on top of an existing model. Fine-tuning costs are low, and it can be added to any open-source model.
Lookahead Decoding
Lookahead decoding doesn’t use a draft model at all. It’s based on Jacobi iteration — a parallel algorithm for solving fixed-point equations. At each step, it runs multiple “future” positions in parallel, treating them as a fixed-point problem converging toward the consistent autoregressive solution.
The advantage: works with any model, no training required. The downside: lower acceptance rates than EAGLE or Medusa on average.
| Method | Speedup | Draft Model Needed | Extra Training |
|---|---|---|---|
| Basic Speculative Decoding | 2–2.5× | Yes (separate model) | No |
| Medusa | 2–3× | No (heads on base model) | Light fine-tune |
| EAGLE-2 | 3–4× | No (feature head) | Light fine-tune |
| Lookahead Decoding | 1.5–2× | No | No |
Speculative decoding is most valuable when:
- Latency is the priority over throughput. It helps time-to-last-token (generation speed) more than time-to-first-token.
- We are serving a single user at a time (low batch size). At high batch sizes, the target model’s compute is already utilized efficiently, and the benefit shrinks.
- The task has a predictable structure that the draft model can exploit — code completion, structured data generation, and domain-specific text see high acceptance rates.
- We are running large models on powerful hardware where memory bandwidth is the actual bottleneck (A100, H100). On smaller GPUs that are compute-bound, the benefit is reduced.
In vLLM, speculative decoding support is built in via the --speculative-model flag. In HuggingFace Transformers, generate() accepts assistant_model for speculative decoding out of the box.
Conclusion
The five techniques across Parts 1 and 2 — quantization, pruning, knowledge distillation, KV caching, and speculative decoding — each consider a different bottleneck in the LLM inference pipeline:
Quantization and pruning reduce the static cost of a model: fewer bits per weight, fewer weights per model. Knowledge distillation reduces the model itself while preserving its capability. KV caching eliminates dynamic redundancy at runtime. Speculative decoding overcomes the sequential generation bottleneck by exploiting parallelism in verification.
None of these techniques works best when used in isolation. A model that’s been distilled to 1B parameters, but isn’t quantized, still costs more than a quantized 7B model at some batch sizes. Speculative decoding helps latency but doesn’t help throughput at large batch sizes. KV caching trades memory for compute, and that trade-off reverses at very long contexts without eviction policies.
The engineers building systems like vLLM, llama.cpp, TensorRT-LLM, and SGLang aren’t applying one technique — they’re composing all of them, tuning the blend for the hardware, workload, and latency requirements at hand. Understanding each technique at the algorithmic level is what lets us reason about those trade-offs clearly.
At DigitalOcean, the GPU Droplets and DigitalOcean AI Platform are designed to handle these workloads efficiently, making it easier to run open-source models at scale without the complexity of managing hyperscaler infrastructure. The optimization techniques we choose—such as the quantization method, whether to use speculative decoding, and how we allocate KV cache memory—have a direct impact on the cost, throughput, and latency of our AI applications. That’s the inference optimization stack. Now you can build on top of it.
Resources
Long-Context Inference at Scale: The Hidden Infrastructure Cost LLM Inference Optimization 101 A Hitchhiker’s Guide to Speculative Decoding A Guide to Distilled Stable Diffusion: Implemented with Gradio Knowledge Distillation: Teacher-Student Loss Explained — Label Your Data Categories of Response-Based, Feature-Based, and Relation-Based Knowledge Distillation — arXiv Dark Knowledge — Geoffrey Hinton, Oriol Vinyals, Jeff Dean (TTIC) Demystifying Knowledge Distillation in Neural Networks — Medium
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
